- 리눅스 환경에서 로그 분석
많은 오픈 소스가 리눅스 ( 우분투 )에서 사용하기 편함
스마트폰에 들어가는 운영체제, 안드로이드 -> 오픈소스
윈도우, ms office -> 오픈소스 아님
* PCRE (정규표현식, Perl Compatible Regular Expression)
- 패턴을 저장, 추출, 검색 등을 할 때 사용
ex) IP주소, 전화번호, 주민등록번호, 이메일 등등
* DLP (Data Loss Prevention) : 개인정보가 외부로 유출되지 않도록 하는 SW, 자체 PC를 검색하기도함 (패턴으로 검색)
* 특수문자
^ : 캐럿 (carrot)
~ : 틸드 (tilde)
* : 아스테리스크 (Asterisk)
[ ] : 브라킷 (bracket)
. : 닷(dot), 포인트
@ : at
[0-9] : 숫자만 사용가능
{3} : 3자리 사용 가능
{1,3} : 1자리~3자리 사용 가능
ex) [0-9]{1,3} : 0~999
A{3} : A를 세자리로 만듦 AAA
[a-z] : a부터 z까지
[a-z]{3} : a부터 z까지 3번 사용 : aaa,aab,aac,....,abc,.....,kjh,.....,zzz -----> 알파벳 소문자3자리
[a-z]{1,3} : a부터 z까지 1~3번 사용 : a,b,c,d,....,aa,ab,ac,....,aaa,aab,aac,....,zzz
[^a-z] : 소문자 아닌것
[^'] : '가 아닌 것
i..o : info(가능) into(가능) .는 문자 1개를 의미하는 와일드 카드
* 특수문자의 Escape 처리를 해주어야 함
- Escape : 특수문자가 고유한 기능을 못하게 하는 것 ( 특수문자 고유한 기능 : - 가 빼지는 것 ( 전화번호에서))
- 특수문자 앞에 \를 붙이는 것
* AWK
- awk는 파일로부터 레코드(record)를 선택하고, 선택된 레코드에 포함된 값을 조작하거나 데이터화하는 것을 목적으로 사용하는 프로그램
- awk 명령의 입력으로 지정된 파일로부터 데이터를 분류한 다음, 분류된 텍스트 데이터를 바탕으로 패턴 매칭 여부를 검사하거나 데이터 조작 및 연산 등의 액션을 수행하고, 그 결과를 출력하는 기능
- awk는 기본적으로 입력 데이터를 라인(line) 단위의 레코드(Record)로 인식
- 각 레코드에 들어 있는 텍스트는 공백 문자(space, tab)로 구분된 필드(Field)들로 분류
awk 참고 블로그 : https://recipes4dev.tistory.com/171
리눅스 awk 명령어 사용법. (Linux awk command) - 리눅스 파일 텍스트 데이터 검사, 조작, 출력.
1. awk 명령어. 대부분의 리눅스 명령들이, 그 명령의 이름만으로 대략적인 기능이 예상되는 것과 다르게, awk 명령은 이름에 그 기능을 의미하는 단어나 약어가 포함되어 있지 않습니다. awk는 최
recipes4dev.tistory.com
* 암호화폐로 보상을 해주는 블로그
https://steemit.com/
우분투 환경에서 작성함

$ echo "Mina Sana Dahyun Jeonyun" | awk '{print $1,$4,$3,$2 }'
$ echo "Mina Sana Dahyun Jeonyun" | awk '{print $1,$4}' | awk '{print $2,$1}'
----> Jeonyun Mina
mina가 $1 jeni가 $2가 됨
* sed : 치환할 때 많이 사용하는 명령
$ sed 's/old/new/g' // old가 new로 바뀜
cf. DNS로그는 구분자를 [**]로 사용함 ㅡㅡ;;
----> awk문은 공백을 구분자로 사용하기 때문에 DNS로그를 읽을 수가 없음...
예제) [**]를 |(파이프)로 치환하려면?
sed 's///g' // 공식
sed 's/[**]/|/g' // 바꿀 내용 입력
sed 's/\[\*\*\]/|/g' // 이스케이프 처리를 위해 \(백슬래시)를 붙임
실습파일 다운로드) 우분투를 실행하고 Firefox에서 아래 사이트에 접속해서 파일을 다운로드 합니다.
https://cafe.naver.com/boanworld/864
* 우분투에 7zip 설치
$ sudo apt install p7zip p7zip-full
$ cd Downloads
- 6번째 컬럼만 골라서 보려면?
$ sudo cat bee_access.log | awk '{print $6}'
- 무슨 행위가 있었는지 보려면? (6~8번 까지 확인)
$ sudo cat bee_access.log | awk '{print $6,$7,$8}'
- 192.168.5.1에서 몇번이나 접속했는지 확인하려면?
$ cat bee_access.log | awk '{print $1}' | sort | uniq -c | sort -rn
----> 212번

- 공격이 언제 시작해서 언제 끝났는지?
$ cat bee_access.log | grep '192.168.5.1' | awk '{print $1,$4,$5}' | head -1 // 첫번째줄은 공격을 시작한 시간
$ cat bee_access.log | grep '192.168.5.1' | awk '{print $1,$4,$5}' | tail -1 // 마지막줄은 공격을 끝낸 시간

* CERT (침해사고 대응팀)
- 회사내에 존재, 보안업체들이 전문인력으로 구성
ex) Ahnlab A-team
* 7zip파일 압축 풀기
$ sudo 7zr x log.7z
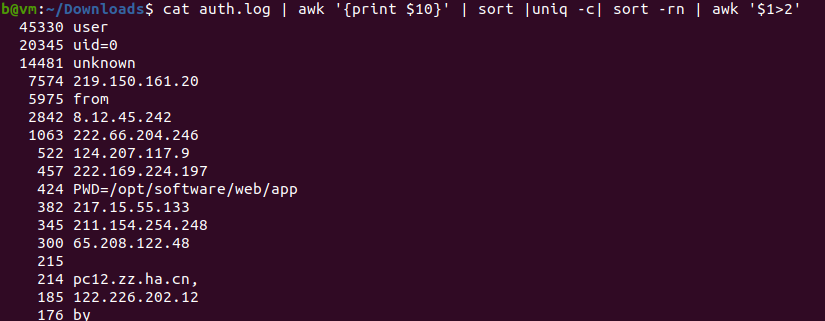
$ tail -10 auth.log

5번째 컬럼이 명령어
- 누구의 권한으로 실행되었는지 확인
$ cat auth.log | awk '{print $10}' | sort | uniq -c | sort -rn

uniq -c : 중복제거
sort -rn : 내림차순
- 3번 이상만 골라서 확인 (1~2번 나온 것은 의미 없음)
$ cat auth.log | awk '{print $10}' | sort | uniq -c | sort -rn | awk '$1>2'
- 그 결과를 저장하려면?
$ cat auth.log | awk '{print $10}' | sort | uniq -c | sort -rn | awk '$1>2' > my.log



- 어떤 명령이 가장 많이 사용되었는지 그리고 몇 번 사용되었는지?
$ tail -10 auth.log
$ cat auth.log | awk '{print $5}' | awk -F"[" '{print $1}' | sort | uniq -c | sort -rn
-----> SSH(외부접속)로 접속한 횟수가 70442번???
-----> CRON(예약작업)으로 D-Day에 동작하도록 설정을 할 수 있음 (악의적 행위가 동작하는 시점이 지정되어 있음)

$ head -20 dv_access.log
- 어떤 페이지를 POST로 요청했는지 확인
- 6번 컬럼은 POST 또는 GET으로 시작하므로 POST만 골라서 보고, 11번 컬럼은 요청한 페이지이므로 아래와 같이 작성
$ cat dv_access.log | awk '$6~/"POST/{print $11}'
$ cat dv_access.log | awk '$6~/"POST/{print $11}' | sort | uniq -c | sort -rn
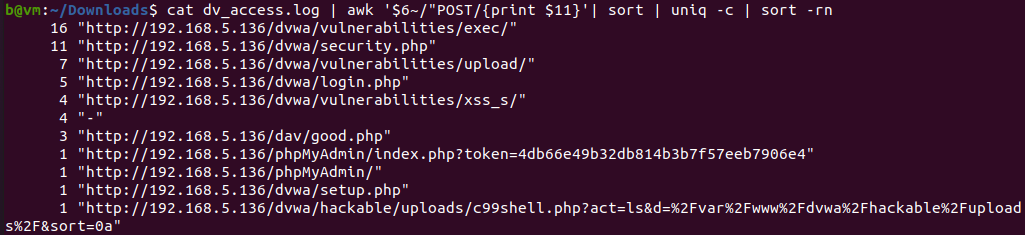
arg는 거의 binary로 되어 있음 머라고 써있는지 알 수 없음
log는 거의 text로 되어있음
* Argus IDS를 설치
- IDS의 대표적인 오픈 소스 : Snort, Suricata, Argus IDS
- Argus IDS의 본체는 네트워크 중간에 배치, Argus의 사용자 콘솔은 사무실에 설치
* Argus IDS Client 설치
$ cd ~
$ sudo apt install flex
$ sudo apt install bison
$ cd Downloads
$ sudo -i // root 권한으로 전환
# cd /home/계정/Downloads
# tar zxvf argus-clients-3.0.8.tar.gz
# cd argus-clients-3.0.8
# ./configure // gcc가 없는 경우, apt install gcc해서 설치하면 됨, byacc도 없다고 하면 마찬가지로 설치
# apt install make
# make && make install
# cd .. (또는 # cd /home/계정/Downloads)
# ra --help
# ra -nzr 1_merged_total.arg -s saddr,sport,daddr,dport // 상당히 많이 나옴

* BPF (Berkeley Packet Filter)
- 자연어 기반의 필터 (자연어는 (미국에 사는 영어사용하는) 인간의 언어)
# ra -nzr 1_merged_total.arg - "src host 192.168.1.122 and udp" // 출발지 IP주소가 192.168.1.122이고 UDP인 패킷만 골라서보기

* DNS (Domain Name Service)
- 정방향 조회: Domain Name을 입력하면 IP주소를 알려주는 것
- 역방향 조회: IP주소를 입력하면 Domain Name을 알려주는 것
- DNS Record
A : 정방향 조회 (IPv4주소를 알려줌)
AAAA 또는 A6 : 정방향 조회 (IPv6주소를 알려줌)
PTR (pointer) : 역방향 조회
cname : 별칭
NS : Name Server의 준말
# head -10 2_dns.log
- 구분자 : [**]
- Query : Client(웹브라우저)가 DNS Server에게 IP주소를 물어보는 것
- Response : DNS Server가 Client(웹 브라우저)에게 IP주소를 알려주는 것
- 3번째 컬럼이 도메인이고, 6번째가 IP주소
- Response 이면서, A로 표시된 것이 정방향 조회의 결과임
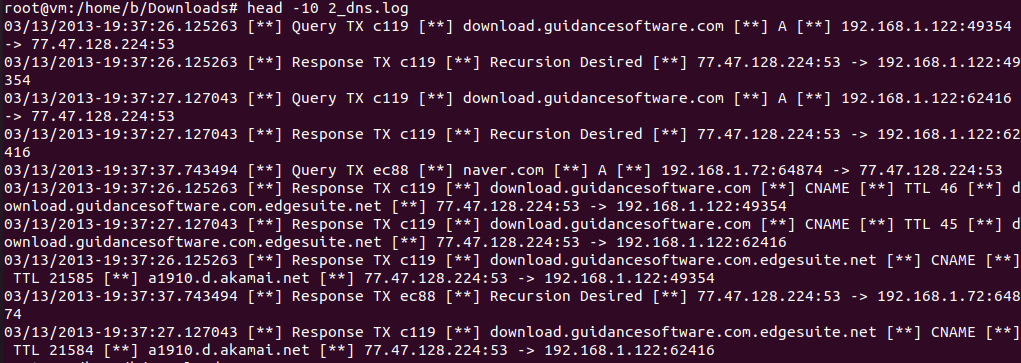
- 구분자를 |로 만든 후, |를 제거할 예정
# cat 2_dns.log | sed 's/\[\*\*\]/|/g' | awk -F"|" '{print $3,$6}'
- 2번째 컬럼이 Response이고 4번째 컬럼이 A인 것만 골라서 추출
# cat 2_dns.log | sed 's/\[\*\*\]/|/g' | awk -F"|" '$2~/Response/ && $4~"A"{print $3,$6}' | sort -u
- 구분자를 없애기 위해서 파이프로 치환 : sed 's/[**]/|/g' (백슬래시 추가:Escape)
- 파이프를 제거 awk -F"|"
- $2에서 Response를 골라내고
- &&는 AND의 의미
- $4에서 A를 골라냄
- $3이 도메인이고, $6이 IP주소이므로 화면에 출력

1번) 192.168.1.0/24(내부망)에서 Web Server에 접속한 로그를 골라서 web.log에 저장
# ra -nzr 1_merged_total.arg - "src net 192.168.1.0/24 and dst port (443 or 80) and tcp" > web.log
# less web.log // PgUp or PgDn

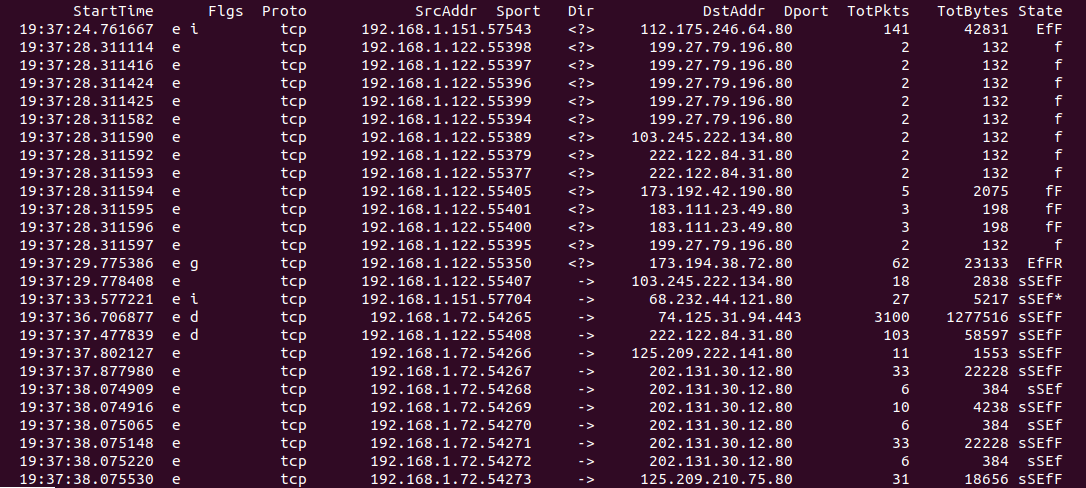
2번) 1번결과가 너무 많이 나오므로 중복을 제거하고 다시 저장
# ra -nzr 1_merged_total.arg - "src net 192.168.1.0/24 and dst port (443 or 80) and tcp" | uniq -c > web.log
cf. uniq -c와 sort -u의 차이점은?
uniq -c : 중복을 제거하고 왼쪽에 개수를 표시
sort -u : 중복만 제거

문제
3. tcp 포트로 출발하는 IP 통계를 구하시오
# ra -nzr 1_merged_total.arg -s saddr - "tcp" | sort | uniq -c | sort -rn
(내림차순 : sort -rn)

문제
4. tcp 를 사용하는 경우 , 상위 10 개의 목적지 IP 통계를 구하시오
# ra -nzr 1_merged_total.arg -s daddr - "tcp" | sort | uniq -c | sort -rn | head -10

4-1) 업로드가 많다는 것은 데이터를 외부로 유출했을 것으로 보고 가장 많은 데이터를 외부로 보낸 사용자를 찾아내려고함
# ra -nzr 1_merged_total.arg -s sbytes, saddr - "tcp" | sort -rn | head -10
sort 는 정렬하라는 의미 ----> 같은 것끼리 묶음
sort -n : 오름차순
sort -rn : 내림차순 (r : reverse, 역순)

5번) 업로드의 양을 IP별로 합산해서 상위 10개를 출력하도록 함
# ra -nzr 1_merged_total.arg -s saddr,sbytes - "tcp" | sort -k 1,1 | awk 'ip==$1{sum=sum+$2;next}{print sum, ip; ip=$1; sum=$2}' | sort -rn | head

문제
6. tcp 통신하는 출발지 IP, 목적지 IP, 목적지 Port 를 추출하시오
# ra -nzr 1_merged_total.arg -s saddr , dport , daddr - " tcp " | sort | uniq -c | sort -rn | awk '{print $1 "\t" $2 "\t" $4 " \t" $3}' | head
# ra -nzr 1_merged_total.arg -s saddr , daddr , stime , dport - "tcp " | awk '{print $1,$2,$4}' | sort | uniq -c | sort -rn > tcp_connection

문제
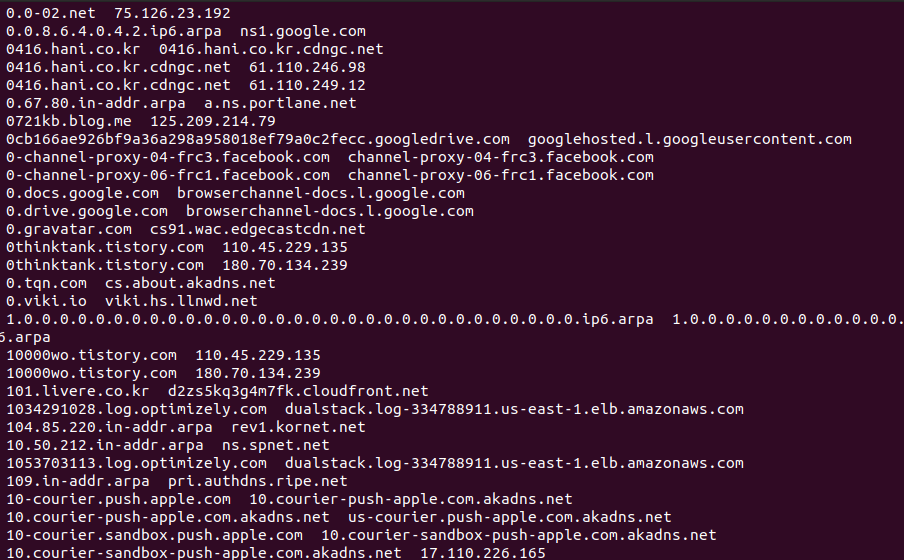
7. 2_dns.log 파일에서 구분자는 파이프로 치환하고 $2 에서 Response 로 시작하며 가 A
인 것들을 골라 $3 와 $6 만 추출하여 dns.lookup 으로 저장하시오
cat 2_dns.log | sed 's/ \[[\*\*\] /|/g' | awk -F"|" '$2~/Response/ && $4~"A"{print $3, $6}' | sort -u > dns.lookup
→ \ 넣는 이유는 정확한 값을 찾으라는 의미로 문자앞에 넣는다 .
space도 넣어서 구분자 사이 공백없이 처리함
2번째 필드 : Response 로 시작
4 번째 필드 : A
출력 필드 : 3,6 필드 , 중복제거 sort u
8번) 목적지IP주소가 사설IP를 제외하려고 함
사설IP만 골라내려면 : /^192.168.|^172.16.|^10./ // ^은 ~~로 시작하는 의미
사설IP가 아닌것을 골라서 보려면: !~/^192.168.|^172.16.|^10./
tcp_connection에서 세번째 컬럼이 목적지IP주소임: $3
$3에서 사설IP가 아닌것을 고르려면: $3!~/^192.168.|^172.16.|^10./
특수문자에 Escape처리해주어야 함: $3!~/^192\.168\.|^172\.16\.|^10\./
* 3번 컬럼에 사설IP가 아닌 공인IP로 되어 있는 것을 골라서 출IP,목IP,Port를 상위 30개를 추출해서 top30파일에 저장하기
$ cat tcp_connection | awk '$3!~/^192\.168\.|^172\.16\.|^10\./ {print $2,$3,$4}' | head -30 > top30


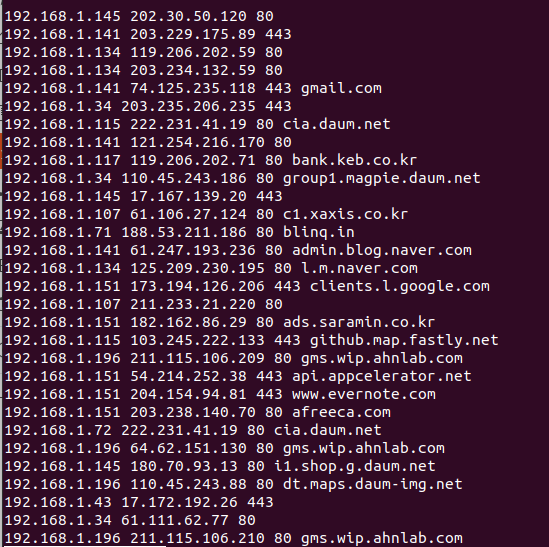
* top30의 목적지 주소에 대한 도메인 주소를 dns.lookup에서 찾아서 dns_matched로 저장하기
# cat top30 | while read line
> do
> dip=$(echo $line | awk '{print $2}')
> domain=$(cat dns.lookup | awk -v ip=$dip '$2==ip {print $1}' | head -1)
> echo $line $domain
> done > dns_matched



less dns_matched
-----> 192.168.1.71 188.53.211.186 80 blinq.in 경로가 가장 의심스러움
문제
9. blinq.in 과 통신한 IP 는 무엇인가
* 또다른 사용자가 blinq.in에 접속했는지 확인하기
# ra -nzr 1_merged_total.arg -s saddr,daddr - "dst host 188.53.211.186" | awk '{print $1}' | sort -u
192.168.1.71
192.168.1.72
------> 위의 2개의 IP주소는 Windows일 것이므로, Windows 포렌식을 통해서 피해 상태를 확인
(blinq.in 이 악성코드를 유포하는 C&C 서버로 확실시 되는 상황)
인도 도메인 의심됨
에버노트 취약점 이용한 공격일수도
$2는 188.~라 확인할 필요 없음

* 참고로 해보세요.
10번) SSH 트래픽을 많이 사용한 로그를 시간(stime),출IP(saddr),목IP(daddr),목port(dport) 순으로 출력하시오.
# ra -nzr 1_merged_total.arg -s stime,saddr,daddr,dport - "port 22" | sort -u
* IP주소와 Port를 분리해서 보고 싶을 때, 중간에 (stime등을) 끼워넣었다가 나중에 빼고 출력
# ra -nzr 1_merged_total.arg -s saddr,stime,sport,daddr,stime,dport - "port 22" | awk '{print $1,$3,$4,$6}' | sort -rn | head -30
* 러시아 사이트에 접속한 사용자는 누구인가?
# cat tcp_connection | awk '$3!~/^192\.168\.|^172\.16\.|^10\./ {print $2,$3,$4}' | sort | sort -rn | head -500 > 500.txt
# cat 500.txt | while read line
> do dip=$(echo $line | awk '{print $2}')
> domain=$(cat dns.lookup | awk -v ip=$dip '$2==ip {print $1}' | head -1)
> echo $line $domain
> done > dns_500
# cat dns_500 | grep "ru"
-------> 192.168.1.72 88.212.196.105 80 counter.yadro.ru
# ra -nzr 1_merged_total.arg -s saddr,daddr - "dst host 88.212.196.105" | awk '{print $1}' | sort -u
-------> 192.168.1.72
* 1000개 사이트를 추출해서 비교
# cat tcp_connection | awk '$3!~/^192\.168\.|^172\.16\.|^10\./ {print $2,$3,$4}' | sort | sort -rn | head -1000 > 1000.txt
# cat 1000.txt | while read line
> do dip=$(echo $line | awk '{print $2}')
> domain=$(cat dns.lookup | awk -v ip=$dip '$2==ip {print $1}' | head -1)
> echo $line $domain
> done > dns_1000
# cat dns_1000 | grep "blinq"
정리) 500개만 했을 때는 blinq.in이 없었음. 1000개 하니까지 blinq.in이 보임
'등등 > 디지털 포렌식' 카테고리의 다른 글
| 디지털 포렌식 - 2일차 (2) | 2022.05.30 |
|---|---|
| AWK로 로그 분석 (0) | 2022.05.26 |
| 디지털 포렌식 - 4일차 (0) | 2022.05.23 |
| 디지털 포렌식 - 3일차 (2/2) (0) | 2022.05.23 |
| 디지털 포렌식 - 3일차 (1/2) (0) | 2022.05.23 |



